Introduction
(Note: As this is a long article, you can download it in pdf format along with USB Power delivery case study. Don’t worry, we don’t ask for email address)
We were presenting our whitebox functional and statistical coverage generation solution, one of the engineer asked, can it take standard specifications as input and generate the functional coverage from it?

Figure 1: Specification to functional coverage magic possible?
I replied “No”. It cannot.
But then after the presentation, questioned myself as to, why not?
No, no still not brave enough to parse the standard specifications use natural language processing (NLP) to extract the requirements and generate the functional coverage from it. But we have taken first step in this direction. It’s a baby step. May be some of you might laugh at it.
We are calling it as high level specification model based functional coverage generation. It has some remarkable advantages. As every time, I felt this is “the” way to write functional coverage from now on
Idea is very simple. I am sure some of you might have already doing it as well. Capture the specification in form of data structures. Define bunch of APIs to filter, transform, query and traverse the data structures. Combine these executable specifications with our python APIs for SystmVerilog functional coverage generation. Voila, poor man’s specification to functional coverage generation is ready.
Yes, you need to learn scripting language (python in this case) and re-implement some of the specification information in it. That’s because SystemVerilog by itself does not have necessary firepower to get it all done. Scared? Turned off? No problem. Nothing much is lost. Please stop reading from here and save your time.
Adventurers and explorers surviving this hard blow please hop on. I am sure you will fall in love with at least one thing during this ride.
How is this approach different?
How is this approach different from manually writing coverage model? This is a very important question and was raised by Faisal Haque.
There are multiple advantages, which we will discuss later in the article. In my view single biggest advantage is making the coverage intent executable by truly connecting the high-level model of specifications to functional coverage. No we are not talking about just putting specification section numbers in coverage plan we are talking about really capturing the specification and using it for generation of functional coverage.
Let me set the expectations right, this approach will not figure out your intent. The idea is about capturing and preserving human thought process behind the functional coverage creation in executable form. So that it can be easily repeated when things change. That’s all. It’s a start and first step towards specifications to functional coverage generation.
Typically functional coverage is implemented as set of discrete independent items. The intent and its connection to specifications are weak to non-existent in this type of implementation. Most of the intent gets either left behind in the word of excel plan where it was written or in the form of comments in the code, which cannot execute.
Making intent executable
Why capturing intent in executable form is important?
We respect and value the human intelligence. Why? Is it only for this emotional reason? No. Making human intelligence executable is first step to artificial intelligence.
Ability to translate the requirements specification into coverage plan is highly dependent on the experiences and depth of specification understanding of the engineer at the moment of writing it. If its not captured in the coverage plan it’s lost. Even the engineer who wrote the functional coverage plan may find it difficult to remember why exactly certain cross was defined after 6 months.
Now this can become real challenge during the evolution and maintenance of the functional coverage plan as the requirements specifications evolve. Engineer doing incremental updates may not have luxury of the time as the earlier one had. Unless the intent is executable the quality of the functional coverage will degrade over period of time.
Now if you are doing this design IP for only one chip and after that if you are throwing it away this functional coverage quality degradation may not be such a big concern.
Let’s understand this little further with example. USB power delivery supports multiple specification revisions. Let’s say, we want to cover all transmitted packets for revision x.
In manual approach we will discretely list protocol data units valid for revision x.
For this listing you scan the specifications, identify them and list them. Only way to identify them in code as belonging to revision x is either through covergroup name or comment in the code.
In the new approach you will be able to operate on all the protocol data units supported by revision x as a unit through APIs. This is much more meaningful to readers and makes your intent executable. As we called out, our idea is to make coverage intent executable to make it adaptable. Let’s contrast both approaches with another example.
For example, let’s say you want to cover two items:
- All packet transmitted by device supporting revision 2.0
- Intermediate reset while all packet transmitted by device supporting revision 2.0
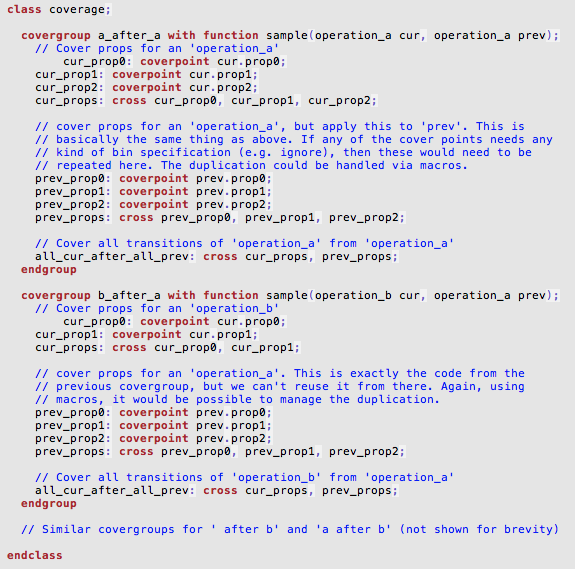
If you were to write discrete coverage, you would have sampled packet type and listed all the valid packet types of revision 2.0 as bins. Since bins are not reusable in SystemVerilog you would do copy and paste them across these two covergorups.
Now imagine, if you missed a packet type during initial specification scan or errata containing one more packet type came out later, you need to go back and add this new type at two different places.
But with this new approach, as soon as you update the specification data structure with new type you are done. All the queries requesting revision x will automatically get updated information. Hence all the functional coverage targeted to revision x will be automatically updated.
Remember initially it may be easy to spot two places where the change is required. But when you have hundreds of covergroups it will be difficult to reflect the incremental changes to all the discrete covergroups. It will be even more difficult when new engineer has to do the update without sufficient background on the initial implementation.
In the USB Power delivery case study you will be able to see how to put this concept into action.
Benefits
What are the benefits of this approach?
With high-level specification model based functional coverage the abstraction of thought process of writing coverage moves up and it frees up brain bandwidth to identify more items. This additional brain bandwidth can significantly help improve the quality of functional coverage plan and hence the overall quality of functional verification.
Benefits of high-level model based functional coverage generation:
- Intent gets captured in executable form. Makes it easy to maintain, update and review the functional coverage
- Executable intent makes your coverage truly traceable to specification. Its much better than just including the specification section numbers which leads to more overhead than benefit
- Its easy to map the coverage from single specification from different components points of view (Ex: USB device or host point of view or PCIe root complex or endpoint or USB Power delivery source or sink point of view) from single specification model
- Easy to define and control the quality of coverage controlled by the level of details in the coverage required for each feature (Ex: Cover any category, cover all categories or cover all items in each category)
- Easy to support and maintain multiple versions of the specifications
- Dynamically switch the view of the coverage implemented based on the parameters to ease the analysis (Ex: Per speed, per revision or for specific mode)
Architecture
How to go about building high-level specification model based functional coverage?
First let’s understand the major components. Following is the block diagram of the high-level specification model based functional coverage. We will briefly describe role and functionality of each of these blocks. This diagram only shows basic building blocks.
Later we will look at the case studies where we will see these blocks in action making their explanations more clear. It will also guide how to implement these blocks for your project as well.
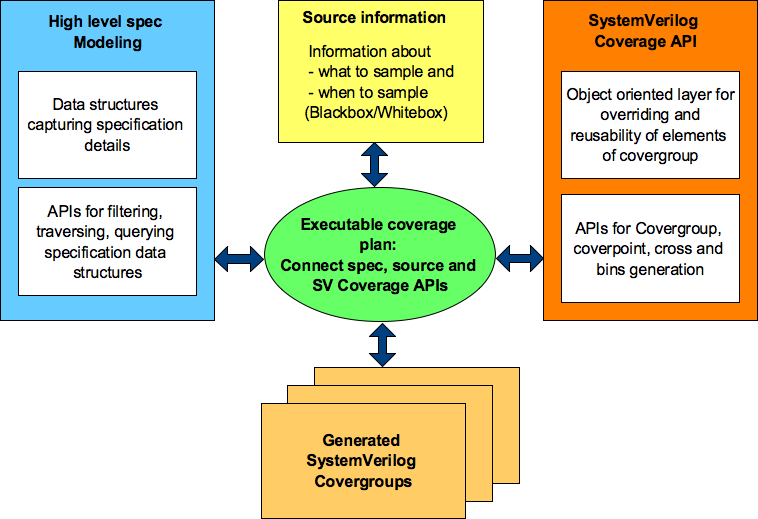
Figure 2: Block diagram of high-level specification model based functional coverage generation
Executable coverage plan
Executable coverage plan is the block that actually hosts all the functional coverage items. It’s coverage plan and its implementation together.
It does the implementation of functional coverage items by connecting the high-level specification model, source of information and SV coverage APIs. The APIs utilized, specification information accessed and relations of various items utilized preserves the intent in executable form.
User still specifies the intent of what to cover.
It won’t read your mind but you will be able to express your thoughts at higher level of abstractions and more closer or specifications and in highly programmable environment that is much more powerful that SystemVerilog alone.
High-level specification modeling
This block is combination of set of data structures and APIs.
Data structures capture high-level information from the specifications. These data structures can be capturing information about properties of different operations, state transition tables representing the state machines, information about timers as to when they start, stop, timeout or graphs capturing various forms of sequences. Idea here is capture the relevant information about the specification that is required for the definition and implementation of the functional coverage. Choose the right form of data structures that fit the purpose. These data structures will vary from domain to domain.
APIs on the other hand process the data structures to generate different views of the information. APIs can be doing filtering, combinations, permutations or just ease access to the information by hiding the complexity of data structures. There is some level of reuse possible for these APIs across various domains.
Using these set of data structures and APIs now we are ready to translate the coverage plan to implementation.
Information source
Specification data structures may define the structure of operations but to cover it, we need to know how to identify the completion of operation, what is the type operation of operation completed and current values of its properties etc.
Information source provides the abstraction to bind the specification information to either test bench or design RTL to extract the actual values of these specification structures. This abstraction provides the flexibility to easily switch the source of coverage information.
Bottom line stores information about sources that are either sampled for information or provides triggers to help decide when to sample.
SystemVerilog Coverage API in Python
Why do we need these APIs, why can’t we just directly write it in SystemVerilog itself?
That’s because SystemVerilog covergroup has some limitations, which prevent the ease of reuse.
Limitations of SystemVerilog Covergroup
SystemVerilog functional covergroup construct has some limitations, which prevents its effective reuse. Some of the key limitations are following:
- Covergroup construct is not completely object oriented. It does not support inheritance. What it means is you cannot write a covergroup in base class and add, update or modify its behavior through derived class. This type of feature is very important when you want to share common functional coverage models across multiple configurations of DUT verified in different test benches and to share the common functional coverage knowledge
- Without right bins definitions the coverpoints don’t do much useful job. The bins part of the coverpoint construct cannot be reused across multiple coverpoints either within the same covergroup or in different covergroup
- Key configurations are defined as crosses. In some cases you would like to see different scenarios taking place in all key configurations. But there is no clean way to reuse the crosses across covergroups
- Transition bin of coverpoints to get hit are expected to complete defined sequence on successive sampling events. There is no [!:$] type of support where the transition at any point is considered as acceptable. This makes transition bin implementation difficult on relaxed sequences
Coverage API Layering
At VerifSudha, we have implemented a Python layer that makes the SystemVerilog covergroup construct object oriented and addresses all of the above limitations to make the coverage writing process more productive. Also the power of python language itself opens up lot more configurability and programmability.
Based on this reusable coverage foundation we have also built many reusable high level coverage models bundled which make the coverage writing easier and faster. Great part is you can build library of high-level coverage models based on best-known verification practices of your organization.
These APIs allows highly programmable and configurable SystemVerilog functional coverage code generation.
Fundamental idea behind all these APIs is very simple.
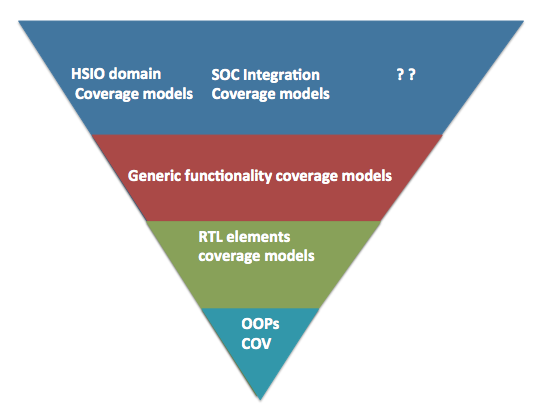
Figure 3: SV Coverage API layering
We have implemented these APIs as multiple layers in python.
Bottom most layer is basic python wrappers through which you can generate the functional coverage along with the support for object orientation. This provides the foundation for building easy to reuse and customize high-level functional coverage models. This is sufficient for the current case study.
RTL elements coverage models cover various standard RTL logic elements from simple expressions, CDC, interrupts to APPs for the standard RTL element such as FIFOs, arbiters, register interfaces, low power logic, clocks, sidebands.
Generic functionality coverage models are structured around some of the standard high-level logic structures. For example did interrupt trigger when it was masked for all possible interrupts before aggregation. Some times this type of coverage may not be clear from the code coverage. Some of these are also based on the typical bugs found in different standard logic structures.
At highest-level are domain specific overage model. For example many high-speed serial IOs have some common problems being solved especially at physical and link layers. These coverage models attempt to model those common features.
All these coverage models are easy to extend and customize as they are built on object oriented paradigm. That’s the only reason they are useful. If they were not easy to extend and customize they would have been almost useless.
Implementation
- Backbone of these APIs is data structure for the SystemVerilog covergroups modeled as list of dictionaries. Each of the covergroup being a dictionary made up of list of coverpoint dictionaries and list of cross dictionaries. Each of the coverpoint and cross dictionaries contain list of bin dictionaries
- These data structures are combined with simple template design pattern to generate the final coverage code
- Using layer of APIs on these data structure additional features and limitations of SystemVerilog covergroup are addressed
- Set of APIs provided to generate the reusable bin types. For example if you want to divide an address range between N equal parts, you can do it through these APIs by just providing the start address, end address and number of ranges
- There are also bunch of object types representing generic coverage models. By defining the required properties for these object types covergroups can be generated
- Using python context managers the covegroup modeling is eased off for the user
Any user defined SystemVerilog code can co-exist with these APIs. This enables easy mix of generated and manually written code where APIs fall short.
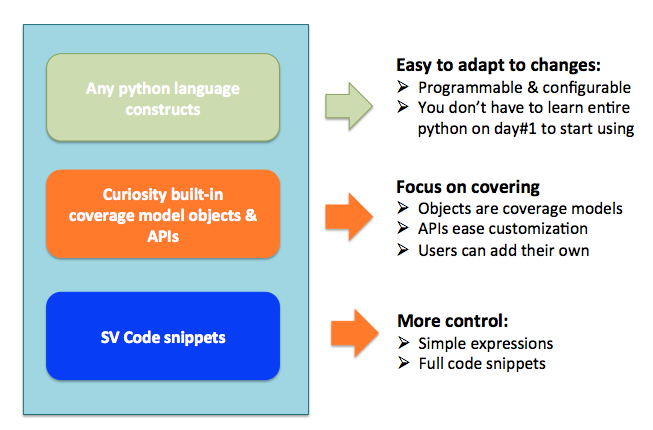
Figure 4: What to expect from APIs
Structure of user interface
All the APIs essentially work on the object. Global attributes can be thought of as applicable to entire covergroup. For example if you specified bins at the global level it would apply to all the coverpoints of the covergroup. Not only the information required for coverage generation but also description and tracking information can be stored in the corresponding object.
This additional information can be back annotated to simulator generated coverage results helping you correlate your high-level python descriptions to final coverage results from regressions easily.
Also the APIs support mindmaps and Excel file generations to make it easy to visualize the coverage plan for reviews.
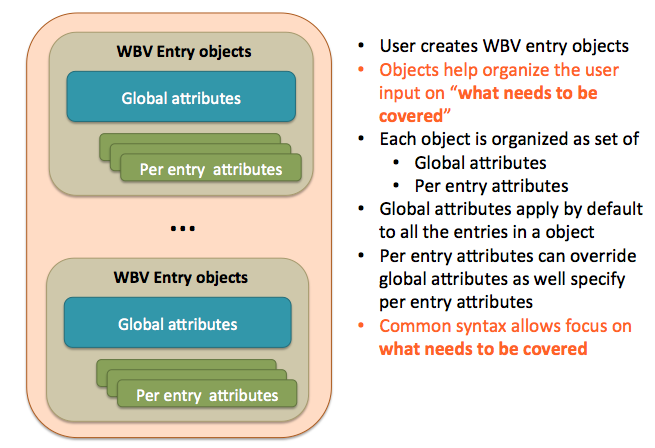
Figure 5: Structure of user interface for objects
Source information
Covergroups require what to sample and when to sample.
This is the block where you capture the sources of information for what to sample and when to sample. It’s based on very simple concept like Verilog macros. All the coverage implementation will use these macros, so that it abstracts the coverage from statically binding to source of the information.
Later these macros can be initialized with the appropriate source information.

Snippet 1: Specifying source information
This flexibility allows using information source from either between the RTL and test bench. Easily be able to switch between them based on need.
Following code snippets showcase how covergroup implementation for simple read/write and address can be done using either RTL design or test bench transactions.

Snippet 2: Coverage generated using testbench transaction
Coverpoints in snippet 2 are sampling the register read write transaction object (reg_rd_wr_tr_obj). Sampling is called on every new transaction

Snippet 3: Coverage generated using DUT signals
Coverpoints in snippet 3 are sampling the RTL signals to extract the read/write operation and address. Sampling is called on every new clock qualified by appropriate signals.
Summary:
Functional coverage is one of the last lines of defense for verification quality. Being able to repeatedly do a good job and do it productively will have significant impact on your quality of verification.
Initially it may seem like lot of work, you need to learn a scripting language and learn different techniques of modeling. But pay off will not only for the current project but throughout the lifetime of your project by easing the maintenance and allowing you to deliver the higher quality consistently.
Download a case study of how this is applied to USB Power delivery protocol layer coverage.