How you execute your first 80% of verification project, decides how long it will take to close the last 20 %.
Last 20%, is hardest because during first 80%, project priorities typically change multiple times, redundant tests get added, disproportionate seeds are allocated to constrain random tests and often distributions on constraints are ignored or effects are not qualified. All this leads to bloated regressions, which are either underworking on right areas or overworking on wrong areas.
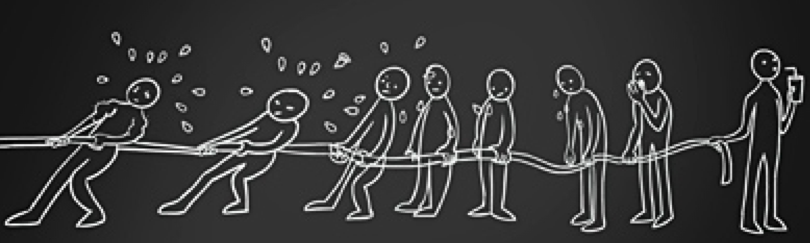
It’s either of the underworking or overworking regression cases that make the closure the last 20% harder and longer. This symptom cannot be identified by the code coverage and requirements driven stimulus functional coverage alone.
Let’s understand what are underworking regressions, overworking regressions and what are their effects.
Overworking regressions
Overworking regressions are overworking because they are failing to focus on right priorities. This happens due to following reasons.
Good test bench architecture is capable of freely exploring the entire scope of the requirement specifications. While this is perfectly right way to architect the test bench but it’s equally important to tune it to focus on right areas depending on priorities during execution. Many designs are not even be implementing the complete specifications and the applications using design may not even be completely using all the features implemented.
Test bench tuning is implemented by test cases. Test case tunes the constraints of stimulus generators and test bench components to make test bench focus on right areas.
Due to complex interaction of test bench components and spread out nature of randomization it’s not possible to precisely predict of the effects of tuning the constraints in test bench. Especially when you have complex designs with lots of configurations and large state space.
In such cases without proper insights, the constrained random could be working in area that you don’t care much. Even when it finds the bugs in this area they end up as distractions rather than value add.
Right area of focus is dependent on different criteria’s and can keep changing. Hence it needs continuous improvisations. It’s not fixed target.
Some of key criteria’s to be considered are following:
- New designs
- Application’s usage scope of design’s feature
- Important features
- Complex features
- Key configurations
- Area’s of ambiguity and late changes
- Legacy designs
Underworking regressions
In contrast to overworking regressions, underworking regressions slack. They have accumulated the baggage of the tests that effectively are not contributing to the verification progress.
Symptoms of underworking regressions are
- Multiple tests exercising same feature in exactly same way
- Tests exercising features and configurations without primary operations
- Tests wasting the simulation time with large delays
- Test with very little randomization getting larger number of seeds
Legacy designs verification environments are highly prone to becoming underworking regressions. This happens as tests accumulate over period of time without clarity on what was done in the past. Verification responsibility shifts hands. Every time it does both design and verification dilutes till new team gets hold of it.
This intermediate state of paranoia and ambiguity often gives rise to lots of overlapping and trivial tests being added to regression. This leads to bloated and underperforming regressions hogging the resources.
Effects of underworking or overworking regressions
Both overworking and underworking regressions reflect in the absurd number of total tests for given design complexity and long regression turn around times.
This results in wastage of time; compute farm resources, expensive simulator licenses and engineering resources. All this additional expenses without desired level of functional verification quality.
Both overworking and underworking regressions are spending their time on non-critical areas. So the resulting failures from them lead to distraction of engineers from critical areas. When number of failures debugged to number of right priority RTL bugs filed ratio starts to go down, it’s time to poke at regressions.
Please note simulator performance is not keeping up with the level of complexity. If you are thinking of emulation keep following in mind:
Hence simulation cycles have to be utilized responsibly. We need to make every simulation tick count.
Which means we need to optimize regressions to invest every tick, in proportion to priority and complexity of the features, to achieve right functional verification quality within budget.
We offer test suite stimulus audits using our framework to provide insights, that can help you align your stimulus to your current project priorities, ensuring stimulus does what matters to your design and reducing the regression turn around time.
Net effect you can optimize your regression to close your last 20% faster.






