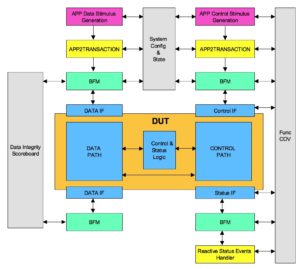
Regressions are process to keep the passing tests in passing state. Ideally in order to do that full regressions should be run for every change.Since the full regression cannot be run for every change, a selected sub set of tests are run before committing the new changes to development code branch. This subset is called check-in regression. This is expected to minimize the possibilities of the spikes in the failure numbers. This is one of the key component to achieve functional verification quality.

Some of the immediate questions about check-in regression would be, how many tests should be selected? What should be the selection criteria? How long should it run?
Duration of check-in regression
Most important question of all is what is the right duration of check-in regression? This is very critical because it limits the speed of the development. Shorter but inadequate check-in regressions may run faster but still slows down development due to failure spikes. Longer but sufficient, may seem right but defeats the purpose of check-in regression. Developers will look for ways to bypass it to avoid the delay. A right balance is the key. Some of the pointers helpful in achieving this balance are discussed below.

Thought process for definition of check-in regression
Check-in regression is all about width and not about depth. It need not go deep in any one area. It should touch all the major features of DUT.
One of the tools driven approach to selects tests for check-in regression can be based on test grading. Run the full regressions, grade your tests and add the tests that provide the highest coverage. Fair enough. Generally problem may not be simpler. There may be multiple test bench areas. Merging the entire test grading across the test bench areas can sometimes be challenging or simulator you are using may not be supporting it. This is one of the simplest approaches and can be a starting point.
Test grading based selection is a theoretically correct answer. That’s because tool can never understand what is really important to your project. Check-in regression should not only broadly cover all the DUT features, but broadly cover features, which are important to project as well. A carefully tailored manual approach is best suited to achieve the best results.
Manual approach to defining the check-in regression is:
- List all your test bench areas if there are multiple test benches
- List all the major configurations parameters and combinations
- List all the tests grouped under major functional areas: Normal operation, error injection, low power etc.
Order each of the areas based their importance in DUT use cases. The features and configuration, which are lower on criticality and use cases, will go down in the list.
Now select few tests from each of the functional areas. Spread them out across the configurations and test benches selected to maximize the unique coverage.
Effective check-in regression definition is not a one-time process. It’s a continuous process till the chip tape out. Tests have to be swapped, added and deleted to get best coverage per test per unit time. Check-in regression is like plant in pot that needs to be continuously trimmed and cared for to get the best out of it.
Test selection criteria for check-in regression
Stability is another very important criteria for test selection in the check-in regression.

Typically selection of directed tests are favored over the constrained random tests. That’s because of the stability they offer. Check-in regression instability causes confusion to developers. Developers will soon lose confidence in the check-in regression. Instability leads to slow down in the development process. Check-in regressions stability is one of the critical bottlenecks of the development speed.
As long as constrained random tests can also offer reasonable stability they can also be part of the check-in regression. Care should be taken to qualify them sufficiently before making them part of the check-in regression. It should not be qualified as part of check-in regressions. This causes problem for everyone and should be avoided. In fact the constrained random tests chosen for the check-in should be run with sufficient seeds and should be curated for some time as part of full regression. When it starts showing good pass rate it can move in to the check-in regression.
Tests that run for long duration should be avoided. When there is sufficient compute power available to run tests in parallel, the long running test will become the bottleneck. If its functionality is must for the check-in regressions consider splitting into multiple smaller tests.
To ensure the shortest run time for selected test ensure that:
- Logging verbosity of the tests should be set to minimum. Additional logging verbosity can add to run time
- Code coverage and Functional coverage should not be enabled. It’s not useful with the check-in regressions and adds to execution time.
- Waveform dumping should not be enabled in check-in regression
Typically above ones are not violated intentionally but accidentally these can happen. Checks should be put in place to prevent it.
Simulator selection criteria for check-in regression
Third party IPs and VIPs vendors have to support it multiple simulators. In such cases tests can be run using the primary simulator in the check-in regression. Compile sanity is sufficient for secondary simulators.
Primary simulator is the one, which has highest licenses. Including test runs with secondary simulators can potentially lead to license bottlenecks. Only bottleneck for check-in regression should be ideally test run time only.
Enforcing check-in regression
Process should be put in place to ensure no code commit to development branch without running the check-in regression. There are cases when developer has run check-in regression and about to commit the code and sees that there is code commits by other developers to the same files. When the updated code is resolved with commits from other developers, check-in regression should be run again. Being pessimistic and paranoid pays.
It’s tempting to cover lot of things in check-in regression. One need to keep in mind check-in regressions is never going to be fully fool proof. It’s meant to reduce major failure peaks and frequency of such peaks. It is like a bulletproof jacket that can save your life most of the time but cannot guarantee it all the time.
Effectiveness of check-in regression should be measured by the number of the failure peaks in full regression due to faulty code changes sneaking through check-in regression periodically. If the frequency of failures is unacceptable check-in regression definition process should be repeated and test list should be updated.