Testbench logging is front end of debug.Debug log content refers to information used for understanding scenario created by test and insights into testbench operation for the purpose of debugging failures.
Good log formatting is not just eye pleasing. Beauty is necessary but its definition is not always eye pleasing. Bottom line is logging should adapt seamlessly to it’s use case model. Beauty of logging is in the eyes of it’s use cases.
Testbench logging is front end of debug. Primary objective for logging is to provide clues into failure and help root cause the issue for failure. Logging objectives should be aligned to three phases of debug. This should be achieved with the help of verbosity.
Test plan would exclusively focus on the stimulus generation. Coverage plan focuses on coverage of intended scenarios through stimulus generation listed in test plan. Checks plan lists the set of the checks performed during the test execution in various components of the test bench.
A check plan lists the checks looking at requirements from two key perspectives:
Is DUT doing, what it should do? This is a positive check. It’s checking is DUT doing what it is expected to do.
Is DUT doing, what it should not do? This is a negative check. It’s checking is DUT doing anything that it is not expected to do or for any unintended side effects after doing what it’s expected to do.
Functional verification is a process of ensuring the fitness of DUT for its purpose.
It involves checking the compliance of the DUT to requirements. This is achieved by first translating the requirements specifications to verification plan.
Is the requirement specification used for designing DUT, the only source of requirements for verification?
Although the requirements specifications used for design are primary requirements for verification but there are additional secondary requirements to be taken into consideration. These secondary requirements stem from the effects of the process of transformations requirements into RTL design used for verification.
Coverage is one of the important metrics in measuring verification quality and helping with verification closure. Lack of functional coverage can lead to expensive bugs like pentium fdiv being discovered late in silicon.
There are two categories of the coverage metrics. First one is code coverage. The simulator tool generates it automatically. Second is functional coverage. Verification engineers develop this by coding.
Code coverage consists of line coverage, condition coverage, expression coverage, FSM coverage and toggle coverage of DUT. Code coverage is topic by itself. Focus of this blog is on the functional coverage.
Functional coverage is not built-in and needs to be manually coded. It’s additional effort for the verification teams. The effort has to justify by providing the additional value on the top of code coverage. So it needs to be carefully planned.
Various sequence combinations coverage cannot be determined
Code coverage as the name says looks at design just as a piece of code. A network switch or processor or fundamentally every RTL design looks same to the code coverage.
Code coverage does not differentiate them from application use case perspective. This means we cannot completely rely on code coverage. Thus code coverage is necessary but not sufficient.
This is where the functional coverage comes in. Functional coverage looks at the design from its application use perspective. A network switch is not same as processor to functional coverage.
In a coverage driven constrained random verification approach the randomness of the stimulus and configuration brings in the uncertainty. Uncertainty of, whether some scenarios really got exercised in certain configuration or not. This is where the functional coverage comes in handy to figure it out with certainty.
Code coverage is based on the DUT code. Significant part of the functional coverage is based testbench code to check if it created the intended scenarios to ensure the correct functionality of the DUT.
Coverage plan writing process
Functional coverage may have certain level of overlap with code coverage. This may have to be done in certain areas for the completeness of the functional coverage. This does not mean, duplicates the entire code coverage in functional coverage.
Functional coverage is luxury. But you cannot have lot of it. A careful thought has to be given where it can provide the maximum impact. The process for coverage plan also should follow “think theoretically and execute practically” as used in test plan writing process.
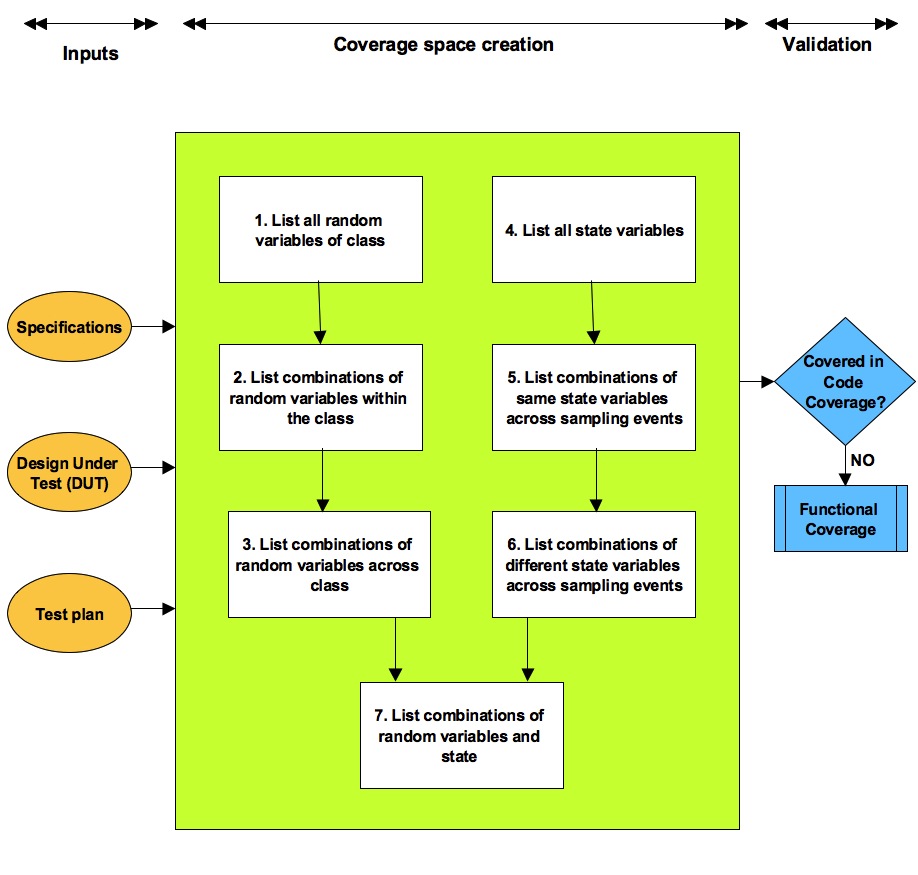
Coverage plan creation takes into consideration 3 inputs:
Using these inputs create the complete functional coverage space using the following 7 steps process described.
Coverage plan writing process
Step#1: List all independent random variables
List all the variables from the specifications that can take multiple values.
Ideally each variable randomized in test bench should be covered. Random variables of each class have to be covered independently.
Typically in the current verification environments, which are object oriented programming based, these variables are encapsulated in to classes. These classes fall in to configurations and transactions.
Configurations can be structure configuration, functional configurations or error configurations. Transactions are encapsulations of request and responses from DUT at various levels of abstractions. All the properties of these classes declared as random should be covered by the functional coverage.
Step#2: List all applicable combinations of random variables within class
Look at the usefulness of combinations of two or more variables related to same unit of information. Same unit of information transforms to variables within the same class.
This could be combination of variables within configurations and transactions may additionally have to be covered in all combinations of values with the other variables.
For example in a full duplex communication protocol it’s not sufficient to cover all transaction types but also cover it in combination with the direction. This is to ensure all legal transactions types have been both transmitted and received by design. Note that transaction type and directions are properties of the same transaction class.
Step#3: List all necessary combinations of random variables across class
Cover the combinations of two or more variables across different units of related information.
This could be combination of variables across the configuration and transaction classes or across various transactions and across various configurations.
For example, to cover all applicable error injection types for all transaction types, cover combination of error injection type in error configuration and transaction type in transaction.
Step#4: List all state variables
Covering certain scenarios or sequences require covering state variables.
State variables can be stored in the test bench or the DUT. As a part of this list all independent state variables that needs to be covered.
Note that to cover certain type of sequences and scenarios new state machines exclusively used for the coverage may have to be developed in the test bench.
For example in USB host subsystem total ports connected state count coverage for active ports coverage.
Step#5: List all necessary sequences of same state variable
Cover the sequences of the same state variables across multiple sampling events.
For example to cover back-to-back stimulus transaction sequences, store last two stimulus transactions as a state. The combinations of these two transaction types stored in state have to be covered.
DUT FSMs are covered by default in code coverage. Limitation of code coverage is, it cannot tell if specific sequences of state transitions have taken place. So some of the key DUT FSMs will have to be additionally covered by the functional coverage.
For example cover sequence of state transitions of a port state machine. USB port going through one of the many state transitions such as: disconnected -> connected -> reset -> enumerated -> traffic -> low power etc.
Step#6: List all necessary combinations of different state variable
Cover the combinations of the different state variables across multiple sampling events.
For example for a N-port USB hub verification environment, need to cover combinations of all port state. This coverage provides insight into, if the hub has experienced various variations of use case scenarios across its multiple ports. This combination can help find out if scenarios such as multiple port connections taking place at same time, one port under rest while data traffic flowing to the other ports, one port under reset while other in low power state etc.
Another example for link layer is combinations of traffic outstanding state and credit state. This combination can help find out if there was outstanding traffic when credits had run out or insufficient credits for outstanding traffic etc.
Step#7: List all necessary combinations of different random variables and state variables
Cover the combinations of random variables and state variables.
For example communication interface such as MIPI UniPro uses PHY that allows multiple power modes. Idea of power modes is to trade speed for power. It also supports multiple traffic classes for supporting quality of service. Covering combinations of the power mode state and randomized traffic class variable of data traffic transaction tells us if all traffic class were active in all power modes.
After the coverage space is created, check if some items already have sufficient coverage in the code coverage. For items that have sufficient coverage in code coverage mark it so and focus on the items that are not covered or partially covered by the code coverage.
Tool’s like curiosity can significantly cut down your functional coverage writing effort with its built-in functional coverage models. Not only its brings time to write it but various built-in coverage models can act as triggers for the functional coverage plan thought process.
When there is no test plan writing process is defined, test plan writing can be lot of fun for first 60 % and then it can soon turn out to be activity filled with anxiety about missing scenarios. To help you overcome this anxiety 8 step test plan writing process is defined below.
Remember primary goal of verification is to ensure:
All features and feature combinations are covered in all configurations
All checks for the illegal and legal behavior expectations are put in place
While writing test plan do not worry about the schedule and resources to execute it. Focus on the completeness. Think theoretically and execute practically.
Before jumping into writing the test plan familiarize with following some of the prerequisites.
Verification strategy
Understand the verification strategy before writing the test plan. Verification strategy contains the technology used for verification, division of verification across test benches and any verification augmentation by emulation etc. (more…)
Test plan should be organized to cater to needs of creation, review, execution and tracking verification to closure.
For the purpose of creation and review, test plans are best organized hierarchically. Primary hierarchy should be something that helps verification team with the execution activity.
Simplest test plan organization can be multiple sections and each section containing multiple tests related to that section. Each test should also list the various variations of the same test to cover all the configurations. Each section header could describe the overall verification strategy for this section and broadly what features its covering. Each test description can focus on the test sequence made up of the stimulus, synchronization and test specific checks. (more…)
Test plan is one of the key component of the verification plan. It’s not a document that is created and thrown in some corner. Test plan is a live map that guides verification to reach destination of meeting verification goals to achieve sign off.
In any layered communication protocol, all the layers above physical layer will utilize some form of protocol data units to accomplish the protocol defined. Here for the simplicity, referring all the protocol data units as transactions.
Physical layer error injection requires a different thought process and will be covered in another blog. Following will focus on the higher layers transaction field error injection.
Transaction field error injection for higher layers of communication protocol will have to cover following. (more…)