What are some of the problems curiosity framework is attempting to solve?
Constrained random verification is one the popular approaches for verifying complex state space designs. Although there has been sufficient focus on the verification methodologies but there is lack of focus on measuring the effectiveness of results delivered by this approach.
Functional coverage is one the key metric used for measuring effectiveness. There are multiple limitations of this metric and how it’s implemented.
- Functional coverage can fundamentally tell you if something is covered but it cannot tell you if the relative distribution of stimulus among features is aligned to your project priorities
- Although black box requirement specification driven coverage is given attention but white box micro-architecture functional coverage is almost ignored or left to mercy of designers
- For coverage metric to stay effective the intent of the coverage should be captured in the executable form. This is possible when we can generate the coverage from executable models of specifications. This approach allows it to evolve and adapt easily to specification changes. Current SystemVerilog covergroup lack firepower to get this done
All these limitations directly affect the functional verification quality achieved. Lower verification quality translates to late discovery of critical bugs.
Curiosity framework is designed to address these challenges to help improve the quality of verification. Primary focus of the framework is on, whitebox functional and statistical coverage generation to fill that missing major gap quickly.
Is the framework targeted to Unit or SOC level verification?
It’s primarily targeted to unit or IP level constrained random verification environment.
However if you are using the functional coverage at SOC level, you can use the framework for generating SOC level functional coverage as well.
Where does the framework-generated coverage fit it?
It’s summarized in the following table.
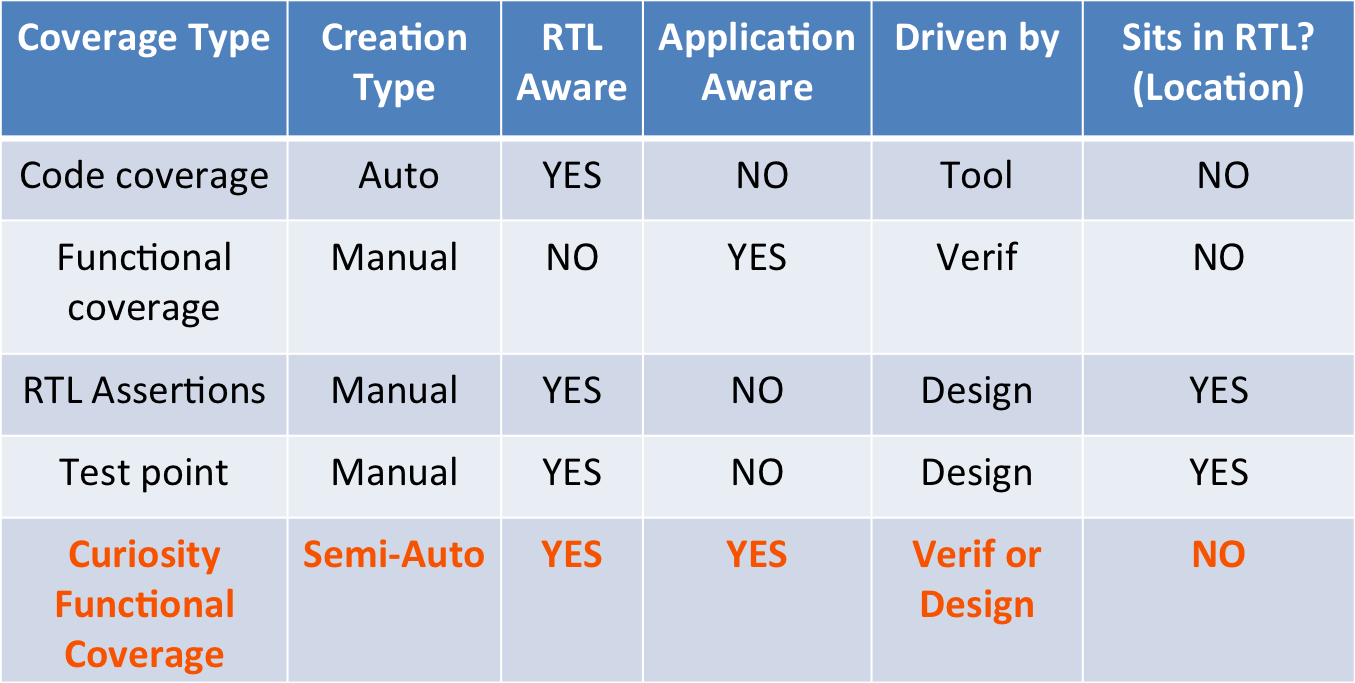
Simulator generates code coverage but it lacks the concurrency and application awareness. By application awareness we mean to code coverage processor design IP or network on chip both are just Verilog code.
Functional coverage fills the gap left by code coverage. But most of it written by the verification teams and focuses on the black box or requirements specification driven stimulus coverage point of view.
RTL assertions are written by the designers to assert their assumptions. Assertion coverage is not same as whitebox functional coverage. For example covering a assertion that checks that grant to request came within 20 clock cycles does not confirm the grant came at different number of clock cycles.
Some designers do go a step ahead and write the test point or coverage embedded within the design to cover for specific scenarios created by the verification environments. But this again is mostly focused on covering the critical scenarios where there is possibility of design breaking. As these sit in RTL, verification engineers are typically hesitant to go add or modify them.
Although both test point and assertion coverage may seem like white box coverage but its not focused sufficiently on the verification intent. This leaves the gap of the white box functional coverage.
This gap is what the framework fills. Its RTL aware that is it can cover the micro-architecture. But that does not mean application aware scenarios cannot be covered. All that coverage needs is what to sample and when to sample. It can come either from RTL or test bench. So anything can be covered even using the RTL signals.
Even designers can easily use it as it does not require comprehensive SystemVerilog knowledge to write the coverage. As this coverage sits outside test bench or RTL it does not dilute your design unlike in-line test point and assertions embedded within the design.
The generated code can be easily disabled from compile and run time. This allows the flexibility to use it for some temporary coverage purposes as well.
What are the input and outputs of the curiosity framework?
Curiosity framework takes input in the form of python code and generates the output in the form of SystemVerilog code.
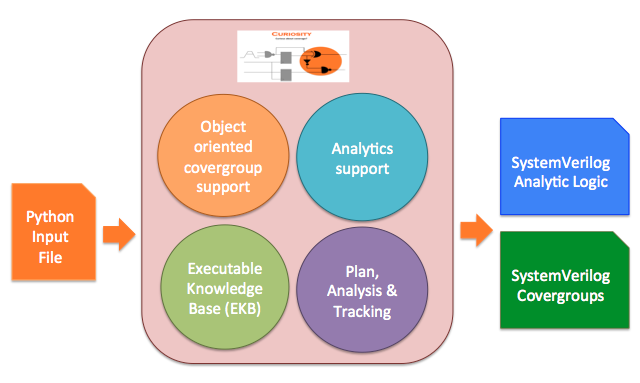
Figure: Curiosity framework Input and Output
Full power of python can be utilized by combining it with set of framework’s pre-defined python objects and APIs for generating the functional coverage, statistical coverage and required monitors.
Generated code needs to be compiled with test bench. Generated functional coverage works like any other user written functional coverage. Coverage results appear in regular functional coverage reports generated by the simulator.
However the framework handles the statistical coverage reports generation. The compiled code has built-in functionality to dump the additional coverage database for statistical coverage. This statistical coverage database is different from simulator’s standard functional coverage database.
Similar to simulator the framework aggregates the statistical coverage from every test using its database at the end of regression. Results of statistical coverage are summarized in the excel format for both per test and full regression level.
How do I integrate the generated code?
Whitebox code generated including both monitors and coverage can be integrated without touching the RTL or test bench. It relies on the hierarchical path references to design to snoop the information directly from design. Don’t worry hierarchical paths are quarantined and managed to ensure the impact of any hierarchy changes is minimal.
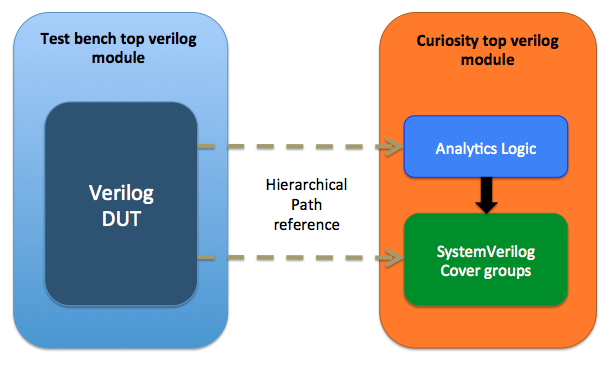
Figure: Integrating the curiosity generated code in test bench
A SystemVerilog module is generated which acts as container for all the monitors and coverage. This module is compiled at the same hierarchy as your test bench top and simulated along with it. That’s it. So all you need to do is to include this additional module to your compile.
What exactly is statistical coverage?
Functional coverage hit proves that scenario or values being covered has happened in the simulation. Coverage goals can be defined as number of times a particular covergroup needs to be hit. However what you cannot out find from coverage reports is relative distribution of stimulus across the various features.
Statistical coverage helps you address this by providing the relative distribution of the stimulus across various features. This helps you align the stimulus to your project priorities. Aligning the stimulus to your project priorities increases the chances of hitting the bugs that matter.
For example you can find out what is the percentage of overall simulation time across either a test or regression a FSM is spending in different states. For example this can provide insights into what is total time spent in initialization, normal operation, low power operations or some modes and configurations. Also imagine being able to find out duration of each clock frequency of dynamic voltage and frequency scaling logic.
Also framework enables you to quickly find out many other types of statistics. Some of them are following:
- Count of any type of events. For example number of times clock gating has taken place.
- Minimum and maximum duration of some signal. This for example can help you find out the
- Minimum and maximum interrupt service latency across regression
- Minimum and maximum duration of a specific timer timeout
- Some events taking place back to back
All these statistics can be found at per test level or across group of tests. This can bring in lot of transparency and clarity especially when you are in last mile of your verification closure.
Why is framework primarily focusing on whitebox functional and statistical coverage?
Whitebox functional coverage is often ignored and bites back hardest. It gets ignored because it falls between the boundary of design and verification engineer.
Although designers do write some of the whitebox coverage but it’s mostly written to cover their assumptions. It’s not written with the intent to check for the stimulus quality.
Also there are areas of overlap between the requirements and micro-architecture specifications that might need special attention. Let’s take an example of a high-speed serial protocol with maximum packet size is up to 1024 bytes. Internal buffers are managed in 256 bytes chunks. Now please note packet sizes around multiple of 256 bytes might be create interesting scenarios for this specific implementation. From black box perspective this size is yet another case but for this implementation it has some special significance. These type of cases are easy to cover using the whitebox approach.
Also for black box coverage implementation sometimes the support from the test bench in terms of trigger or transaction may not exist. Typically RTL is ready much ahead of its verification environments, it makes sense to leverage it. By tapping at right points and with little massaging of signals most of the information required for coverage can be created very quickly.
How much python do I need to learn to get started?
How much UVM did you learn when you got started? Most of us started with examples and boilerplate codes. Gradually picked up different UVM base classes to master based on the requirements where we needed the changes.
Similar technique can be applied here as well. You need to understand the basic data types, control structures, looping, subroutines and bit of objects. If you already know any other scripting language like perl, it will be easier to pick it up.
We have rich set of examples for every API and object supported. You can start off with them and slowly master the details of python. But more you learn the more you will be able unleash the power of the framework.
How can framework help me at different phases of my project?
If you are just starting a project then you can consider doing high-level specification model based coverage generation.
If you are in the middle of the project and you have already written good chunk of SystemVerilog coverage code manually then you can consider using the flow for new features and quickly covering bug fix verification.
If you are towards the closure, you can try out the APPs for the micro-architecture functional coverage generation. It will quickly give you benefit of the whitebox functional coverage which is typically ignored.
Does framework by itself decides what to cover? Does it have any intelligence?
This is a framework and not a push button tool. It does require user inputs. However, It does have some intelligence. It’s in the form of pre captured customizable high-level coverage models. User will still need to select the right models and has to provide the inputs. It will be much lesser effort than having to write everything in SystemVerilog. Also the libraries act as hints and clues as to what is possible. Thus helping improve the quality of the functional coverage written.
We believe for achieving functional verification quality, two sources of specifications must be considered:
[1] Requirements specification
[2] Micro-architecture specification
While #1 gets its fair share of attention #2 is almost ignored by verification teams.
To help them with #2, we have developed APPs for micro-architecture statistical and functional coverage analysis. To these APPs you provide the high level specifications of your design, like FIFOs, Arbiters, register interfaces, FSMs, clocks, low power intent etc. based on these, it automatically generates the various coverage models. Some of the results from these APPs are showcased in case study.
Please note intent here is not to cover these basic RTL blocks, but it’s about analyzing whether stimulus is doing what matters to the design using these known points as references.
Input for micro-architecture coverage generation is high level micro-architectural description captured in the form of data structures. Based on the type of the element, tool has built-in knowledge of what to cover for it.
For #1: Requirements specification we are doing high level specification model based coverage generation (HLSMCG). This is a first step towards specification to functional coverage generation.
Input is in the form of capturing the relevant details of specification in the form of data structures. Using these data structures of information user can invoke appropriate reusable coverage models to generate the coverage.
What if the generated micro-architecture functional coverage is not relevant? Do we still need to cover those?
I hear what you are saying. Typically generated functional coverage tends to very comprehensive and based on regular patterns. Hence it can have at times have coverage that you may not interested for your design. Framework may think certain coverage as relevant but you may think it’s not relevant at this point. This may create extra work to close this coverage.
It’s a valid concern. Most of the code generation solutions fail because with the higher level of abstractions controllability is lost. We have taken care to balance abstraction and controllability. You can control the generated coverage at two level of granularity.
First is at higher granularity control of quality of coverage generated. We offer multiple levels of quality on generated coverage. This allows the control of verbosity of the functional coverage generated. It directly controls number of covergroups, coverpoints or bins generated.
Second is finer granularity of user control. All generated coverage is object-oriented in nature. So the generated coverage object can be extended and required modifications in the form of add, edit or delete can be done in python itself. Since the modifications are in derived class nothing in the base class gets lost. If you change your mind on something its easy to tweak it back unlike when you really changed the original code. I know you can argue about using version control to get back the changes but don’t forget out of sight out of mind.
Yes, this is still additional work but its more easier and cleaner to do it in python than to do it in the simulator interface. Remember the coverage exclusion experience you had last time in simulator interface. It will not be like that. Even the exclusions and updates can be written as programs making it lot easier and bit of fun.
FIFO, Arbiters etc. type of standard micro-architecture elements are pre-verified, why are they being covered?
Whitebox functional coverage that framework generates is focused on the assessing the stimulus quality using these standard micro-architecture elements (FIFO, Arbiters etc.) as reference. They are used to figure out whether stimulus is doing what matters to design.
For example, when we cover the count of the FIFO EMPTY -> FIFO FULL cycling, focus is not really on the FIFO. We know FIFO is well qualified (is it?) but the logic surrounding FIFO may not be. Idea of this coverage is to see when FIFO goes through these extremes can the surrounding logic deal with it.
Another example is, for simple arbiter we cover whether first request came from different requesters. Please note here designers may not find it interesting from their arbiter design operation point of view. But from traffic generation point of view it might provide us some interesting insights like can the overall system deal with the traffic starting from different streams and have we done it.
Why should I write functional coverage in Python – why not directly in SystemVerilog?
SystemVerilog functional covergroup construct has some limitations, which prevents its effective reuse. Some of the key limitations are following:
- Covergroup construct is not completely object oriented. It does not support inheritance. What it means is you cannot write a covergroup in base class and add, update or modify its behavior through derived class. This type of feature is very important when you want to share common functional coverage models across multiple configurations of DUT verified in different test benches and to share the common functional coverage knowledge
- Without right bins definitions the coverpoints don’t do much useful job. The bins part of the coverpoint construct cannot be reused across multiple coverpoints either within the same covergroup or in different covergroup
- Key configurations are defined as crosses. In some cases you would like to see different scenarios taking place in all key configurations. But there is no clean way to reuse the crosses across covergroups
- Transition bin of coverpoints to get hit are expected to complete defined sequence on successive sampling events. There is no [!:$] type of support where the transition at any point is considered as acceptable. This makes transition bin implementation difficult on relaxed sequences
At VerifSudha, we have implemented a Python layer that makes the SystemVerilog covergroup construct object oriented and addresses all of the above limitations to make the coverage writing process more productive. Also the power of python language itself opens up lot more configurability and programmability.
Reuse is the way you can store your verification knowledge in the executable form by encoding it as configurable high-level coverage models.
What is the overall functionality provided by the framework?
Based on this reusable coverage foundation we have built many reusable high level coverage models bundled which increase the abstraction and make the coverage writing easier and faster. Great part is you can build library of high-level coverage models based on best-known verification practices of your organization.
These APIs allows highly programmable and configurable SystemVerilog functional coverage code generation.
Fundamental idea behind all these APIs is very simple.
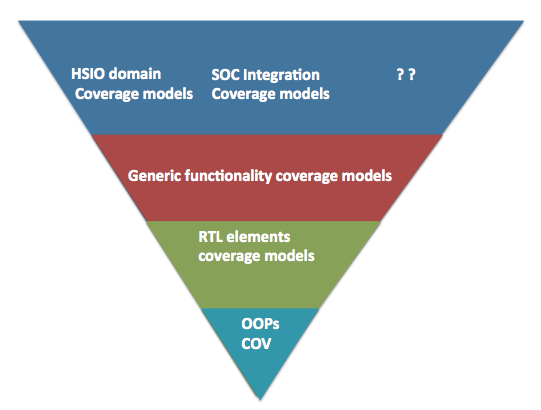
Figure 3: SV Coverage API layering
We have implemented these APIs as multiple layers in python.
Bottom most layer is basic python wrappers through which you can generate the functional coverage along with the support for object orientation. This provides the foundation for building reusable and customizable high-level functional coverage models. Description of other layers follows.
RTL elements coverage models cover various standard RTL logic elements from simple expressions, CDC, interrupts to APPs for the standard RTL element such as FIFOs, arbiters, register interfaces, low power logic, clocks, sideband signals.
Generic functionality coverage models are structured around some of the standard high-level logic structures. For example did interrupt trigger when it was masked for all possible interrupts before aggregation. Some times this type of coverage may not be clear from the code coverage. Some of these are also based on the typical bugs found in different standard logic structures.
At highest-level are domain specific overage model. For example many high-speed serial IOs have some common problems being solved especially at physical and link layers. These coverage models attempt to model those common features.
All these coverage models are easy to extend and customize as they are built on object oriented paradigm. That’s the only reason they are useful. If they were not easy to extend and customize they would have been almost useless.
What are some of the benefits of adoption towards the end of project?
Time is short here. In short term you can start using the built-in APPs. Short term we mean within couple of weeks.
Built-in APPs provide key insights about to whether your stimulus is doing what matters to your design. Most of the time designers are tied up or even when they write functional coverage for design they end of focusing more on their assumptions rather than overall verification intent.
Our APPs are targeted to provide you insights from verification point of view. With the high-level description of your micro-architecture as input, you can get the insights on your stimulus within matter of few weeks.
Check out this case study on UART.
What are some of the benefits of adoption in the middle of project?
In the middle of the project you might have already written part of your functional coverage plan manually. However you can still use the statistical coverage.
You can start using the statistical coverage for your requirements specifications. It can provide you insights about the stimulus quality and any tuning required making it effective to verify your requirements.
You can also quickly target writing functional coverage for the intersection of the micro-architecture and requirements specification. You can accelerate writing this type of functional coverage with high-level objects available.
Also you can quickly generate the functional coverage for making sure the critical bug fixes are verified completely.
What are some of the benefits of adoption right from beginning of the project?
You can start modeling your requirements specifications. Using these high-level models you can start generating both the functional and statistical coverage. One of the biggest benefits of this approach apart from accelerating the coverage writing process is capturing the intent in executable form.
Benefits of high-level model based functional coverage generation:
- Intent gets captured in executable form. Makes it easy to maintain, update and review the functional coverage
- Executable intent makes your coverage truly traceable to specification. Its much better than just including the specification section numbers which leads to more overhead than benefit
- Its easy to map the coverage from single specification from different components points of view (Ex: USB device or host point of view or PCIe root complex or endpoint or USB Power delivery source or sink point of view) from single specification model
- Easy to define and control the quality of coverage controlled by the level of details in the coverage required for each feature (Ex: Cover any category, cover all categories or cover all items in each category)
- Easy to support and maintain multiple versions of the specifications
- Dynamically switch the view of the coverage implemented based on the parameters to ease the analysis (Ex: Per speed, per revision or for specific mode)
Beyond this you can start building reusable functional and statistical coverage models based on your organization’s best-known practices and critical bugs found. It can be shared in executable form across the teams. This will help you avoid the similar mistakes repeated across teams. The post-silicon bugs found need just end up in the presentations. You can make them executable and quickly identify if similar coverage gaps are relevant on other design IPs of your organization.
Can I include my own hand written code in the generated code?
Yes, this is possible. You can easily mix your hand written code with the generated code.
What if VerifSudha went out of business after our adoption?
Yes as customer you might worry about that. Keep this in mind all the generated code is SystemVerilog. Its not encrypted. Worst case you can still maintain it without needing to go back to Python.
Of-course you will loose the productivity and programmability that python brings in.
We don’t even close the code coverage completely, why should we consider the functional coverage generation?
If you don’t have time to close code coverage means you don’t even have time to write the functional coverage.
This is where a framework that can shorten your time to write and analyze the functional coverage gives you an opportunity to get benefits of functional coverage.
Also remember there might be more value in looking at our APP generated micro-architectural functional coverage than closing last few percentages of code coverage filled mostly with exceptions.
Are there some case studies available for reference?
Yes at present there are two case studies available.
We have a case study on UART, demonstrating the value of statistical coverage and reusable functional coverage models.
Another one is case study with USB Power delivery protocol layer coverage generated from high level specification model.
There is one small article on how Pentium FDIV bug could have been prevented if there was micro-architecture coverage for the LUT used in the floating-point divider implementation.
Can I get an evaluation version of the framework to try it out?
Yes, we have a web-based interface to try out various built-in examples. There are installation hassles here. However you cannot compile and run anything with your test bench on web interface.
Framework can also be set it up in your own environment where you can integrate the generated code to try it out in your regression.
Contact anand@verifsudha.com for more details.
How can we quickly realize its benefits of the framework without investing our engineer’s time and effort?
First of all with plenty of built-in examples and python guide bundled it should be quick for your engineers to get started.
However if you are under schedule pressure or first want to establish value, we do offer services to generate the whitebox functional and statistical coverage for your design.
Quickset way to see things in action would be, through our APPs we can quickly fill the gap of typically missing micro-architecture functional coverage for you. Providing you the confidence and opportunity to discover the bugs hidden deep down the micro-architecture and specification intersections. Even if you are about 80% verification complete, you can still find these services useful by helping you discover possible coverage holes 3x-5x faster than doing manual coverage development.
Our services provide you an opportunity to tune your regressions to your current project priorities enabling your stimulus to do what matters to your design. This in turn increases the chances of finding the bugs that matter faster. We can help you make your constrained random stimulus work hard for you.
We can also help you to get your high-level specification model based functional coverage off the ground.
Our services do come with money back guarantee. You decide the value delivered. We then take pro-rated pricing based on your evaluation of value delivered. If you perceive it as zero, zero it is. You can optionally help us by giving your feedback as to how we can improve our value delivered to you. Try us for few weeks, nothing to loose.
Is the framework targeted to just enhance the coverage writing productivity?
Our vision with framework is to equip you to audit the stimulus quality quickly at any stage of the project.
You can generate simple functional coverage literally in minutes. Let’s say you want to simply cover different values of some signal in your design. All that you need to do is provide signal name and the event to sample typically related clock is simplest choice. Framework will take care of generating the covergroup and instancing the covergroup. If the signal is present in multiple instances, no problem you can specify the instance list and automatically coverage can be either generated for each instance or merged across instances. This ease will encourage you to write more coverage without thinking twice and that’s how the quality starts to improve. You can find out anything you want to find out. Let’s say you are writing a directed test and you want to step-by-step look at if what you wanted is happening you can simply cover it. More transparency and accountability can be brought in for verification.
Constrained random approach is like an automatic machine gun. Although it gets the job done for complex state space problems but it can waste lot of simulation cycles. Have you ever thought about coverage per tick of simulation time invested? May be you are not worried about wastage of simulation cycles but this wastage can delay the discovery of critical bugs. This is something no one wants.
Statistical coverage is a unique feature present only in our framework to provide you bigger picture about what your stimulus is doing. Using this you can tune and measure if stimulus is aligned to your current project priorities.
Tuning your stimulus to current project priorities can end up providing a pleasant byproduct of reduction in the simulation time wastage. This reduction leads to improvement in the regression turn around time. We can bet the savings achieved by reduced simulator license usage and reduced compute resource usage, just by itself can justify the investment made in our solutions.
Let’s get real here, it might seem we have vested interest here (Yes, we do) but we totally believe that functional coverage is most important metric for simulation based verification quality.
Following is the aerial panoramic view of “The Great Migration, Kenya”.

Image courtesy: airpano.com
Those are the wilder beasts crossing the river during migration. Hungry crocodiles are waiting in this river at this bottleneck point. You are thinking what this has to do with the functional coverage?
We think constrained random tests are like these wilder beasts. They also run wild in the pastures of regressions. It’s very difficult to know what they are going to do. But we can streamline them by forcing them to cross the river at only some specific points. Those points can be your functional coverage. Ideally we imagine verification lead to sit there like crocodile and catch the weak wilder beasts (tests) passing through it. Our framework can help just do that.
It’s difficult for verification lead to keep reviewing and auditing each of the tests and test bench infrastructure developed by large and spread out teams. However we are not saying it should not be done. It must be done but when the schedule pressure hits the thing to guard is gate of functional coverage. Functional coverage is last line of defence. As long as functional coverage is comprehensive, overall results delivered from the test bench will not suffer. However test bench and test case quality from maintainability may suffer under schedule pressures but the functional coverage allows you to control the quality of results delivered. The only way to maintain the quality of test bench and tests from maintainability point of view is to do periodic refactoring after abusing them to meet the milestones.
So improving the functional coverage writing productivity holistically through planning, implementing and tracking the results in single view will have significant impact on the verification quality. Our eyes are on that prize of quality.